- Dapatkan link
- X
- Aplikasi Lainnya
Untuk melakukan clustering dalam SQL Server Itegration Services, maka siapkan dahulu database AdventureWorksDW2012, karena saya akn menggunakan database tersebut. Bila kamu punya database sendiri silahkan gunakan. Karna kita akanbelajar menghasilkan cluster dan cara membaca cluster tersebut. Clustering adalah salah satu teknik data mining yang digunakan untuk mengkelompokan data bedasarkan kriteria tertentu yang mirip. Contoh customer ingin kita kelompokan bedasarkan jumlah pendapatan maka customer tersebut akan dianalisa dan dikelompokan sesuai dengan kemiripan data mereka. Sehingga kita bisa melihat kelompok customer dengan pendapatan tertinggi, bisa memiliki ciri-ciri apa yang sama, bisa jadi kepemilikan mobil dan rumah menjadi ciri yang membuat customer dalam kelompok yang sama. Kita tidak pernah tahu apabila semuanya dilakukan secara manual, mengingat jumlah data yang sangat banyak. Lalu database adventure work jangan dianggap sebagai data yang besar. Adventure Works hanyalah data contoh dan ukurannya sangat kecil.
Contoh penggunaannya adalah setelah dilakukan clustering maka kita bisa menentukan barang apa yang akan kita jual ke customer tersebut atau melihat customer yang berada dalam 1 cluster memiliki persamaan apa dalam membeli barang. Sehingga kita bisa membuatkan barang custom bagi cluster tersebut. Atau kita balik pola pikirnya, dari data yang tercluster 85%, ditemukan bila orang tersebut mempunyai mobil maka tempat tinggal dan tempat kerja berjarak lebih dari 8KM. Maka kita bisa cari 15% sisanya dan memberikan penawaran mereka mengenai mobil yan kita miliki. Semua ini sangat bergantung pada data yang kamu miliki. Sehingga sangat diperlukan seorang user/pemilik/pengguna data tersebut terlibat dalam pembangunan OLAP. Kenapa user/pemilik/pengguna data dilibatkan karena mereka yang menggunakan data tersebut dan mereka yang paling kenal dengan data mereka.
Contoh lain adalah hasil clustering ini digunakan untuk membentuk profil customer dan kita bisa lihat bahwa customer yang dalam 1 cluster memiliki pola belanja seperti apa, atau barang apa yang akan mereka beli. Itulah gunanya cluster. Sekarang kita akan coba mempraktekan clustering menggunakan SQL Server Data tools. SQL Server Data tools bisa di-install dengan menggunakan SQL Server Developer. Jangan menggunakan SQL Server Express, atau merasa memiliki SQL Server Developer karena sudah dapat menggunakan SQL Server Management Studio.
Pertama buka SQL Server Data Tools, buat solution baru dengan nama Clustering, untuk projectnya sendiri gunakan Analysis Services Multidimensional and Data Mining Project Template.
Pada bagian kanan ada solution explorer, klik kanan di sana dan pilih New Data Source Option, pada welcome page click next dan kemudian kita mendefinisikan koneksi yang akan kita gunakan. Sekali lagi di sini jangan menggunakan koneksi yang ada di list, buatlah koneksi baru. Pada Connection Manager Pilih yang Native OLE DBSQL Server Native Client 11.0 Kemudian pilihlah server name yang kamu gunakan. Di sini jangan menggunakan Windows Authentication, gunakan SQL Server Authentication dan masukan user name password dari akun SQL yang kamu gunakan, Akun yang kamu gunakan sebaiknnya memiliki permission untuk membaca dan menulis ke dalam database Adventure Works DW 2012. kemudian pilih database, lakukan test connection lalu tekan ok bila koneksi sudah berhasil. Untuk nama biarkan default saja.
Untuk yang lupa password SQL Server dapat menggunakan cara seperti berikut
Buka SQL server Management--> log in dengan menggunakan windows aunthetication
Masuk ke object explorer-->Security folder-->login folder
Klik kanan account sa atau akun yang dibuat saat instalasi SQL Server -->properties
Ketikan SQL Password yang baru dan lakukan konfirmasi.
Gunakan nama akun dan password yang kamu baru saja ganti di dalam membangun koneksi.
Setelah selesai buka solution explorer dan klik kanan pada data source views lalu pilih new data source views. Pada halaman welcome wizard klik next, Pilih koneksi yang baru saja kamu buat dan klik next. Kita akan mencoba mengkelompokan customer yang kita miliki, jadi kita akan menggunakan tabel customer, gunakan tabel dimCustomer. Klik next lalu berikan nama pada view yang baru saja dibuat, saya akan menggunakan nama MineCustomer dan klik finish.Akan lebih baik bila kamu masuk ke dalam SQL server Management studio dan melihat terlebih dahulu struktur data dari dimCustomer dan mempelajari data tersebut.
Setelah view berhasil dibuat maka kita akan kembali membuka solution explorer dan melihat folder mining structure, klik kanan di sana dan buat new mining structure. Pada halaman welcome klik next dan kemudian pilih radio button from existing relational database or data warehouse, klik next dan pilih create mining structure with a mining model, pada combobox yang ada pilih microsoft clustering lalu tekan next. Kemudian pilih view datasource yang baru saja kita buat dengan nama Mine Customer, tekan next lalu akan ada dua checkbox pastikan yang tercentang hanya checkbox case. Pada halaman berikutnya kita akan melihat kolom yang ada dalam dim customer, pastikan CustomerKey memiliki checkbox key yang tercentang. Lalu untuk saat ini kita coba kelompokan pendapatan yang mereka miliki pertahun(YearlyIncome sebagai prediction) bedasarkan input CommuteDistance, HouseOwnerFlag,NumberCarsOwned(ketiga kolom ini harus memiliki check pada checkbox input) lalu klik next. Pastikan tipe data yang dimiliki benar, kalau sudah tekan finish dan save solution yang kamu buat. Kemudian pada solution explorer yang di sebelah kanan, cari nama project klik kanan pilih deploy.
Nanti akan muncul pertanyaan "kenapa harus memasukan prediction?" Pertanyaan ini adalah hal yang wajar karena kita melakukan clustering. Sehingga secara logika hanya perlu mengkelompokan tidak perlu memberikan prediksi. Maksudnya prediction adalah dicluster bedasarkan apa. Contoh yearly income, maka data akan dicluster bedasarkan income yang ada. Lalu apa kesamaan apa yang ingin dicari dari yearly income tersebut. itulah gunanya atribut yang ada, dalam kasus ini kita mencari, kepemilikan rumah, jarak transportasi, jumlah mobil yang dimiliki. Sedangkan bila prediction tidak dimasukan maka pada hasil akhir akan terjadi error. yang terjadi di tempat saya adalah tidak memberikan hasil apapun.
Sekarang kita akan melihat hasil dari clustering yang dilakukan. Pada layar harusnya akan keluar beberapa tab.
 Pilih tab mining model viewer maka kamu akan melihat cluster yang terbentuk beserta kedekatan antar cluster.
Pilih tab mining model viewer maka kamu akan melihat cluster yang terbentuk beserta kedekatan antar cluster.
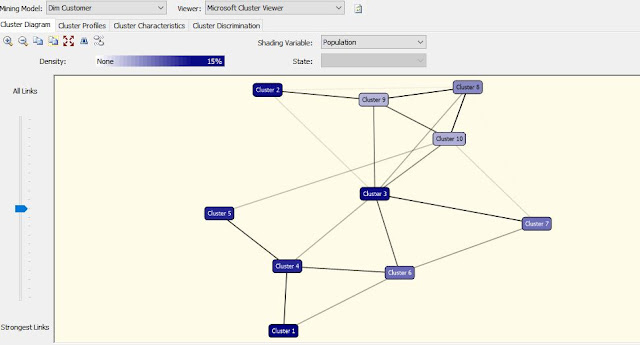 Kita lihat di sini ada beberapa cluster dan kedekatan(garis) antar cluster, default awal dari cluster ini adalah jumlah data di dalam cluster tersebut. Kalau ingin mengubah coba lihat di shading variable. Dari sana bisa kamu ganti sesuai dengan kebutuhan yang kamu perlukan, misal perlu melihat cluster jumlah mobil yang dimiliki maka gantilah di shading variable ini. Saat kamu telah mengganti shading variable maka state yang ada di bawahnya akan berubah dan kamu bisa menggunakan itu untuk melihat sesuai dengan pembagian yang kamu miliki. Contoh kamu ingin mencari customer mana yang terkelompok dengan bedasarkan jumlah mobil maka ganti shading variable dan kamu akan melihat isi dari kolom itu di state, dan state itu bedasarkan data yang ada dalam kolom numbersOfCarOwned.
Kita lihat di sini ada beberapa cluster dan kedekatan(garis) antar cluster, default awal dari cluster ini adalah jumlah data di dalam cluster tersebut. Kalau ingin mengubah coba lihat di shading variable. Dari sana bisa kamu ganti sesuai dengan kebutuhan yang kamu perlukan, misal perlu melihat cluster jumlah mobil yang dimiliki maka gantilah di shading variable ini. Saat kamu telah mengganti shading variable maka state yang ada di bawahnya akan berubah dan kamu bisa menggunakan itu untuk melihat sesuai dengan pembagian yang kamu miliki. Contoh kamu ingin mencari customer mana yang terkelompok dengan bedasarkan jumlah mobil maka ganti shading variable dan kamu akan melihat isi dari kolom itu di state, dan state itu bedasarkan data yang ada dalam kolom numbersOfCarOwned.

Ketika shading variable saya ganti dan state saya ganti menjadi low. Maka kita akan melihat bahwa cluster 1, cluster 3, cluster 4, cluster adalah kelompok orang yang memiliki jumlah mobil antara 0-1. Kalau kamu ganti shading variable maka kamu bisa melihat cluster dengan variable yang lain dan akan ada kedekatan dan kepadatan cluster yang berbeda. Hal ini dikarenakan variable yang kamu pilih dan state yang ada. Tergantung dengan analisa yang ingin kamu lakukan. Misal ingin mentarget customer dengan jumlah mobil 1-3 maka kita bisa melihat pada cluster 2, cluster 3,cluster 4, cluster 5, cluster 6, cluster 9. Bila ingin target customer yang lain gantilah shading variablenya dan lihatlah hasilnya.
 Hasil clusternya berubah, dan kita bisa melihat hubungan antar cluster. Jadi dari cluster 6 adalah orang-orang yang memiliki rumah dan mobil antara 1-3. Kalau ingin melihat secara keseluruhan ganti tab menjadi cluster profile maka kamu akan melihat kesimpulan dari data yang tercluster beserta atribut mereka.
Hasil clusternya berubah, dan kita bisa melihat hubungan antar cluster. Jadi dari cluster 6 adalah orang-orang yang memiliki rumah dan mobil antara 1-3. Kalau ingin melihat secara keseluruhan ganti tab menjadi cluster profile maka kamu akan melihat kesimpulan dari data yang tercluster beserta atribut mereka.
 Kita ambil contoh cluster 5, cara bacanya adalah ada 2317 data dan semua orang ini tidak memiliki rumah(0), jumlah mobil mereka semua ada 2, dan pendapata mereka diantara 10.000,00 hingga 57.305,78. Begitu pula dengan cluster lainnya. Jika ingin mencari customer dengan pendapatan tertinggi maka kita dapat melihat pada cluster 8. Sebagian orang pada cluster 8 belum memiliki rumah, sehingga bila mau jual rumah yang mewah. Targetkan pada customer pada di cluster 8 yang belum memiliki rumah. Kalau jumlah data pada cluster 8 kurang memenuhi maka kita bisa menggunakan cluster yang memiliki kedekatan dengan cluster 8 dan dalam kasus kita adalah cluster 9 dan 10, saya melihat ini dari ketebalan garis yang terbentuk pada house owner flag di gambar sebelumnya.
Kita ambil contoh cluster 5, cara bacanya adalah ada 2317 data dan semua orang ini tidak memiliki rumah(0), jumlah mobil mereka semua ada 2, dan pendapata mereka diantara 10.000,00 hingga 57.305,78. Begitu pula dengan cluster lainnya. Jika ingin mencari customer dengan pendapatan tertinggi maka kita dapat melihat pada cluster 8. Sebagian orang pada cluster 8 belum memiliki rumah, sehingga bila mau jual rumah yang mewah. Targetkan pada customer pada di cluster 8 yang belum memiliki rumah. Kalau jumlah data pada cluster 8 kurang memenuhi maka kita bisa menggunakan cluster yang memiliki kedekatan dengan cluster 8 dan dalam kasus kita adalah cluster 9 dan 10, saya melihat ini dari ketebalan garis yang terbentuk pada house owner flag di gambar sebelumnya.
Untuk yang lupa password SQL Server dapat menggunakan cara seperti berikut
Buka SQL server Management--> log in dengan menggunakan windows aunthetication
Masuk ke object explorer-->Security folder-->login folder
Klik kanan account sa atau akun yang dibuat saat instalasi SQL Server -->properties
Ketikan SQL Password yang baru dan lakukan konfirmasi.
Gunakan nama akun dan password yang kamu baru saja ganti di dalam membangun koneksi.
Setelah selesai buka solution explorer dan klik kanan pada data source views lalu pilih new data source views. Pada halaman welcome wizard klik next, Pilih koneksi yang baru saja kamu buat dan klik next. Kita akan mencoba mengkelompokan customer yang kita miliki, jadi kita akan menggunakan tabel customer, gunakan tabel dimCustomer. Klik next lalu berikan nama pada view yang baru saja dibuat, saya akan menggunakan nama MineCustomer dan klik finish.Akan lebih baik bila kamu masuk ke dalam SQL server Management studio dan melihat terlebih dahulu struktur data dari dimCustomer dan mempelajari data tersebut.
Setelah view berhasil dibuat maka kita akan kembali membuka solution explorer dan melihat folder mining structure, klik kanan di sana dan buat new mining structure. Pada halaman welcome klik next dan kemudian pilih radio button from existing relational database or data warehouse, klik next dan pilih create mining structure with a mining model, pada combobox yang ada pilih microsoft clustering lalu tekan next. Kemudian pilih view datasource yang baru saja kita buat dengan nama Mine Customer, tekan next lalu akan ada dua checkbox pastikan yang tercentang hanya checkbox case. Pada halaman berikutnya kita akan melihat kolom yang ada dalam dim customer, pastikan CustomerKey memiliki checkbox key yang tercentang. Lalu untuk saat ini kita coba kelompokan pendapatan yang mereka miliki pertahun(YearlyIncome sebagai prediction) bedasarkan input CommuteDistance, HouseOwnerFlag,NumberCarsOwned(ketiga kolom ini harus memiliki check pada checkbox input) lalu klik next. Pastikan tipe data yang dimiliki benar, kalau sudah tekan finish dan save solution yang kamu buat. Kemudian pada solution explorer yang di sebelah kanan, cari nama project klik kanan pilih deploy.
Nanti akan muncul pertanyaan "kenapa harus memasukan prediction?" Pertanyaan ini adalah hal yang wajar karena kita melakukan clustering. Sehingga secara logika hanya perlu mengkelompokan tidak perlu memberikan prediksi. Maksudnya prediction adalah dicluster bedasarkan apa. Contoh yearly income, maka data akan dicluster bedasarkan income yang ada. Lalu apa kesamaan apa yang ingin dicari dari yearly income tersebut. itulah gunanya atribut yang ada, dalam kasus ini kita mencari, kepemilikan rumah, jarak transportasi, jumlah mobil yang dimiliki. Sedangkan bila prediction tidak dimasukan maka pada hasil akhir akan terjadi error. yang terjadi di tempat saya adalah tidak memberikan hasil apapun.
Sekarang kita akan melihat hasil dari clustering yang dilakukan. Pada layar harusnya akan keluar beberapa tab.



Bagaimana data ini bisa digunakan, tentu saja untuk keperluan macam-macam Setelah clustering maka kita bisa melihat customer dengan profile yang mirip. Sehingga penawaran akan barang yang dimiliki bisa berbeda untuk setiap customer. Sekali lagi, masalah bagaimana data bisa digunakan sangat bergantung pada orang yang memiliki dan menggunakan data ini pada keseharian mereka. Karena merekalah yang memiliki dan memiliki pengalaman pada bidang bisnis yang menggunakan data tersebut.
Komentar
Posting Komentar